今日はGoogleが開発した MediaPipe という機械学習ライブラリを使って、手のトラッキングを行ってみたいと思います。
下の画像はGoogle MediaPipe の公式サイトにあるものですが、 MediaPipe を使うことで、顔や目、手や全身の動きなどを検出できます。
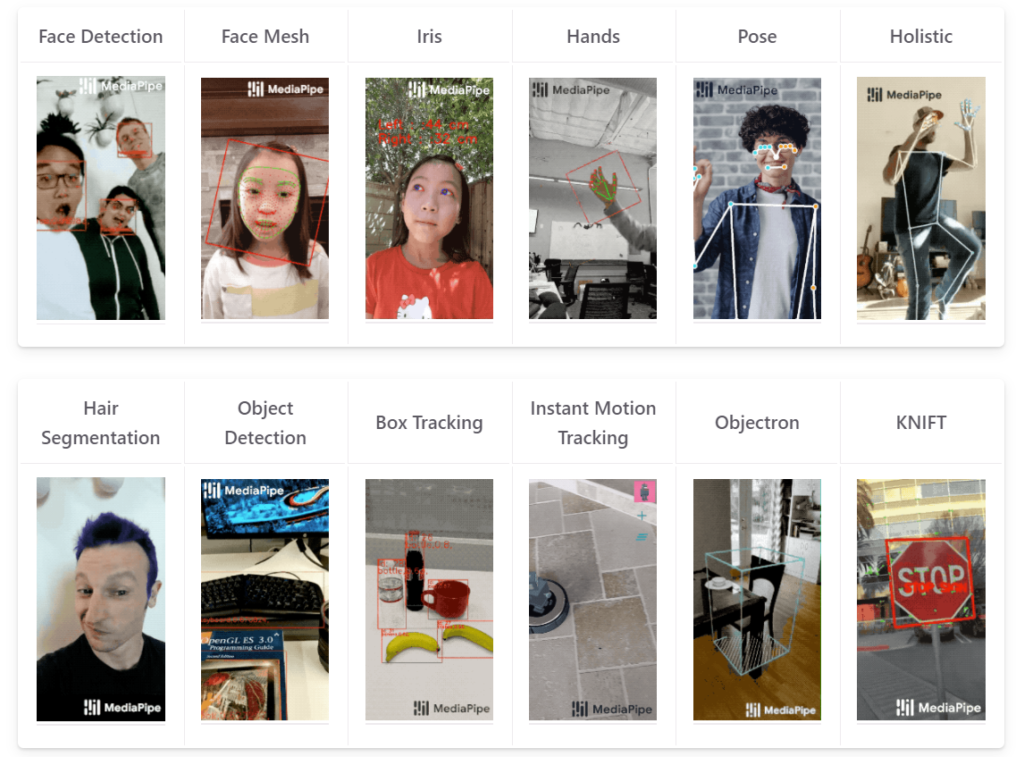
今回はこのうち手の検出をしてみたいと思います。
MediaPipe Hands
https://google.github.io/mediapipe/solutions/hands.html
準備
まずは MediaPipe モジュールをインストールします。以下のようにpipコマンドで簡単にインストールできます。
|
1 |
pip install mediapipe |
サンプルプログラム1:手を検出する
まずは手を検出する簡単なプログラムを作ってみます。ソースコードは以下の通りです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
import cv2 import mediapipe as mp import time cap = cv2.VideoCapture(0) # 手を検出するモデルを作成する mp_hands = mp.solutions.hands mp_draw = mp.solutions.drawing_utils hands = mp_hands.Hands() while True: success, img = cap.read() imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # モデルで手を検出する results = hands.process(imgRGB) if results.multi_hand_landmarks: # 手が検出された場合 for hand_lms in results.multi_hand_landmarks: mp_draw.draw_landmarks(img, hand_lms, mp_hands.HAND_CONNECTIONS) # 手のランドマークを描画する cv2.imshow("Image", img) key = cv2.waitKey(1) & 0xFF if key == ord('q'): break cap.release() cv2.destroyAllWindows() |
これを実行すると以下のようになります。
簡単にプログラムの解説をします。
|
5 |
cap = cv2.VideoCapture(0) |
Webカメラと接続しています。私の環境ではUSBカメラが1つだけでしたので0番目のカメラを指定していますが、複数のカメラがある場合は番号が違うかもしれませんのでご注意ください。
|
7 8 9 10 |
# 手を検出するモデルを作成する mp_hands = mp.solutions.hands mp_draw = mp.solutions.drawing_utils hands = mp_hands.Hands() |
ここで MediaPipe の手を検出するモデルと、描画用のオブジェクトを作成しています。
|
12 13 14 15 16 17 18 19 20 21 |
while True: success, img = cap.read() imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # モデルで手を検出する results = hands.process(imgRGB) if results.multi_hand_landmarks: # 手が検出された場合 for hand_lms in results.multi_hand_landmarks: mp_draw.draw_landmarks(img, hand_lms, mp_hands.HAND_CONNECTIONS) # 手のランドマークを描画する |
Whileループ内でWebカメラから1フレーム画像を読み込んだあと、OpenCV形式の色フォーマット(BGR)からRGBフォーマットに変換しています。変換した画像を MediaPipe モデル hands の process関数に渡してやると結果 results が返ってきます。
もし手が検出された場合は、results.multi_hand_landmarks が None 以外の値になっているので if 文で判定をしています。その後、検出された手のランドマークを線で結んでいます。手のランドマークとは以下のように、各指の関節や先端、手根などの特徴点のことです。それぞれの特徴点には番号が割り振られています。

そのあと23行目で画像を表示しています。
またqボタンが押された場合、ループを抜けるようになっています。
|
23 24 25 26 27 |
cv2.imshow("Image", img) key = cv2.waitKey(1) & 0xFF if key == ord('q'): break |
サンプルプログラム2:人差し指の先端に印をつける
つぎにプログラムを少し変更し、人差し指の先端に少し大きい丸をピンク色で描画するようにしてみました。
ソースコードはこちら。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
import cv2 import mediapipe as mp import time cap = cv2.VideoCapture(0) # 手を検出するモデルを作成する mp_hands = mp.solutions.hands mp_draw = mp.solutions.drawing_utils hands = mp_hands.Hands() while True: success, img = cap.read() imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # モデルで手を検出する results = hands.process(imgRGB) if results.multi_hand_landmarks: # 手が検出された場合 for hand_lms in results.multi_hand_landmarks: for id, lm in enumerate(hand_lms.landmark): if id == 8: h, w, c = img.shape cx, cy = int(lm.x*w), int(lm.y*h) # 画像のピクセル値としてランドマークの場所を検出する cv2.circle(img, (cx, cy), 15, (255, 0, 255), cv2.FILLED) mp_draw.draw_landmarks(img, hand_lms, mp_hands.HAND_CONNECTIONS) # 手のランドマークを描画する cv2.imshow("Image", img) key = cv2.waitKey(1) & 0xFF if key == ord('q'): break cap.release() cv2.destroyAllWindows() |
実行した様子はこちら。
変更した個所(21~25行目)を説明します。
- 人差し指の先端は8番目のランドマークに相当しますので、if文で人差し指の先端かどうかをチェックしています(22行目)。
- 各ランドマークの位置情報が記録されている変数(ここではlm.xとlm.y)は画像内での位置を比率(0~1.0)として表現していますので、元の画像のピクセル値と掛け合わせることで、人差し指の先端の位置をピクセル値として取得することができます(23および24行目)。
- cv2.circle関数で人差し指の先端位置に半径15ピクセルのピンク色(BGR=255, 0, 255)円を描いています(25行目)。
サンプルプログラム3:指先の軌跡を描く
手の検出に関するMediaPipeの使い方については以上ですが、ちょっとした遊び心でプログラムを変更してみました。人差し指の先端に描いたピンク色の丸が軌道を描くようになっています。
ソースコードはこちら。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
import cv2 import mediapipe as mp import time cap = cv2.VideoCapture(0) # 手を検出するモデルを作成する mp_hands = mp.solutions.hands mp_draw = mp.solutions.drawing_utils hands = mp_hands.Hands() xx = [] yy = [] while True: success, img = cap.read() imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # モデルで手を検出する results = hands.process(imgRGB) if results.multi_hand_landmarks: # 手が検出された場合 for hand_lms in results.multi_hand_landmarks: for id, lm in enumerate(hand_lms.landmark): if id == 8: h, w, c = img.shape cx, cy = int(lm.x*w), int(lm.y*h) # 画像のピクセル値としてランドマークの場所を検出する xx.append(cx) yy.append(cy) if len(xx) > 10: # ●の表示は10個までにする xx.pop(0) # 最初の要素を削除する yy.pop(0) for x, y in zip(xx, yy): cv2.circle(img, (x, y), 15, (255, 0, 255), cv2.FILLED) mp_draw.draw_landmarks(img, hand_lms, mp_hands.HAND_CONNECTIONS) # 手のランドマークを描画する else: xx.clear() yy.clear() cv2.imshow("Image", img) key = cv2.waitKey(1) & 0xFF if key == ord('q'): break cap.release() cv2.destroyAllWindows() |
実行した様子はこちら。
変更した場所の説明をします。
- まず指先のx座標、y座標それぞれを格納しておくリスト変数(xx, yy)を作成しています(12,13行目)。
- 人差し指の先端の座標をそれらリスト変数に格納していきます。今回は10個まで表示するようにしてあり、リストの要素が10個を越えた場合は最初の要素を削除しています(27~31行目)。
- リストに格納されている個数分、それぞれの位置にピンク色の丸を描画しています(32~33行目)。
- 手がカメラ映像から外れた場合、つまり手の検出がされなかった場合は指先の座標を格納しているリストをクリアしています(35~37行目)。
サンプルプログラム4:指先の軌跡を半透明にする
おまけでもう1つ。ランドマークの描画をなくし、指先に描画するピンク色の丸を半透明にしてみました。
ソースコードはこちら。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
import cv2 import numpy as np import mediapipe as mp import time cap = cv2.VideoCapture(0) # 手を検出するモデルを作成する mp_hands = mp.solutions.hands mp_draw = mp.solutions.drawing_utils hands = mp_hands.Hands() xx = [] yy = [] while True: success, img = cap.read() imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # モデルで手を検出する results = hands.process(imgRGB) img_out = img.copy() if results.multi_hand_landmarks: # 手が検出された場合 for hand_lms in results.multi_hand_landmarks: for id, lm in enumerate(hand_lms.landmark): if id == 8: h, w, c = img.shape cx, cy = int(lm.x*w), int(lm.y*h) # 画像のピクセル値としてランドマークの場所を検出する xx.append(cx) yy.append(cy) if len(xx) > 10: # ●の表示は10個までにする xx.pop(0) # 最初の要素を削除する yy.pop(0) img_mask = np.zeros_like(img, np.uint8) for x, y in zip(xx, yy): cv2.circle(img_mask, (x, y), 15, (255, 0, 255), cv2.FILLED) # 半透明にする mask = img_mask.astype(bool) alpha = 0.5 img_out[mask] = cv2.addWeighted(img, alpha, img_mask, 1-alpha, 0)[mask] else: xx.clear() yy.clear() cv2.imshow("Image", img_out) key = cv2.waitKey(1) & 0xFF if key == ord('q'): break cap.release() cv2.destroyAllWindows() |
実行した様子はこちら。
変更点は以下の通りです。
- 半透明にするには「マスク」といって、半透明にしたい部分だけをくり抜いたような画像データを作成します。そのためにここで元の画像をコピーしています(21行目)。
- さらに元の画像を同じサイズのデータ配列を作成します。この配列は0で初期化されていますので、真っ黒な画像データだと思ってください。このデータ配列に対して、ピンク色の丸を描画します。ピンク色の丸を描画したデータ配列をbool型で二値化します。つまり円を描いた部分はTrue、それ以外はFalseとなります(35~39行目)。
- 半透明にする度合い(アルファ値)をここではちょうど半分の0.5にしています。この後、OpenCVのaddWeighted関数で元の画像(img)のアルファ値を「alpha」、マスク画像のアルファ値を「1-alpha」と指定しています。ですので、変数alphaの値を0にするとピンク色の丸は不透明になりサンプルプログラム3と同じ動作になりますし、alphaの値を1にすると完全に透明になって●が表示されなくなります(40行目)。
- さいごに最初にコピーしておいた元の画像(img_out)のマスク部分(配列maskの内容がTrueになっている部分)を、元の画像(img)とマスク(img_mask)をそれぞれ0.5の重みをかけて合成した画素情報に置き換えています。これでピンク色の丸が半透明になり、背景も見える画像になります(41行目)。
さいごに
今回のプログラムは私が MediaPipe を勉強するために作ったものですが、私の子供に見せたところディズニーアニメの魔法使いのようだと喜んで遊んでいました。小学生くらいの子供であれば面白がってくれるのではないかと思います。
- 投稿タグ
- プログラミング
