概要
私が書いている「投資ブログ」でInstagramの投稿記事を紹介することがあります。ただ1つ困ったことがあって、Instagramのページでは投稿記事の画像をブラウザの操作からダウンロードできません。
たとえば通常、ブラウザに表示された画像上で右クリックをすると「名前を付けて画像を保存…」という項目が出てきます。
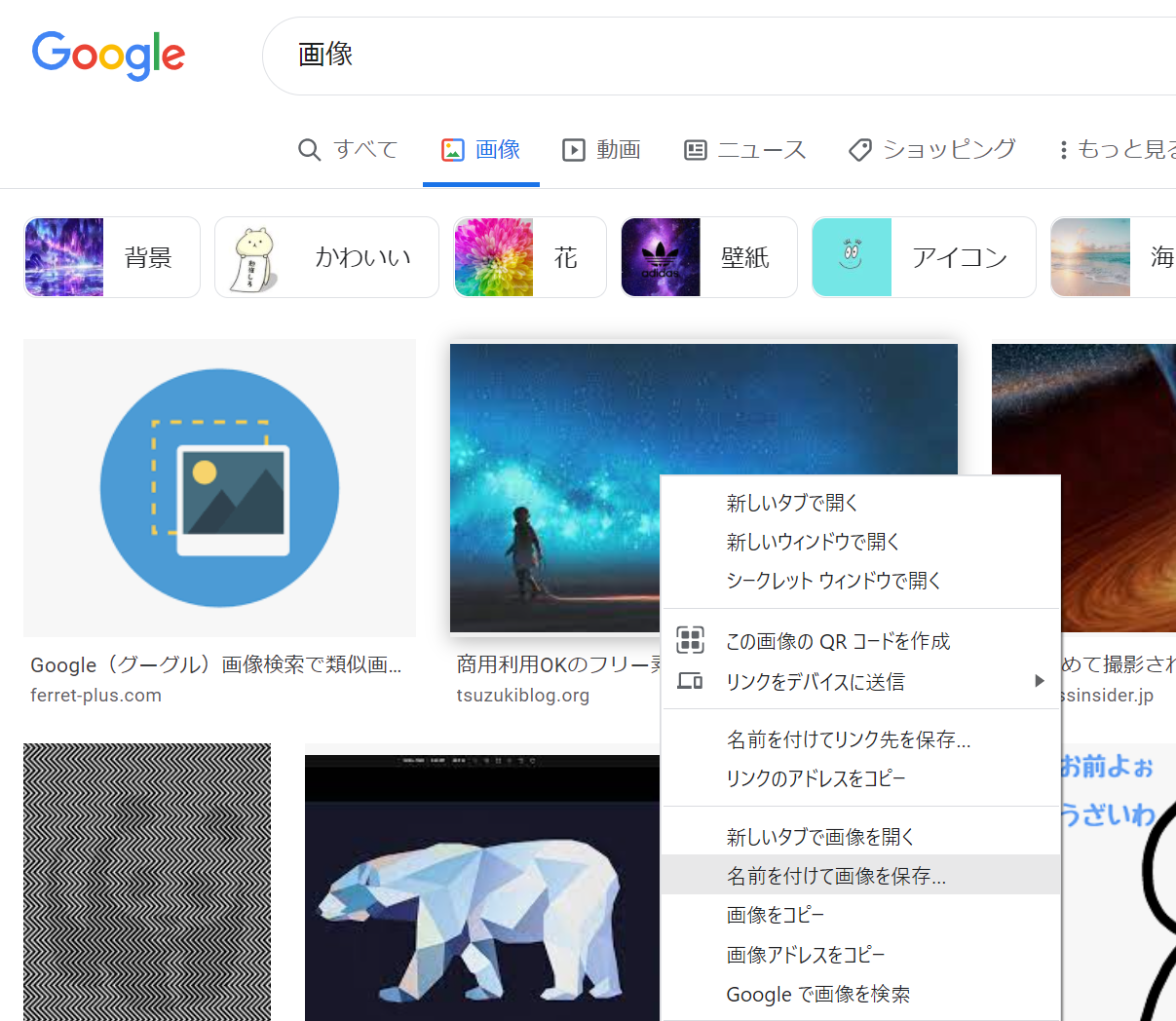
でもInstagramのページでは画像上で右クリックしても「名前を付けて画像を保存…」の項目が出てきません。
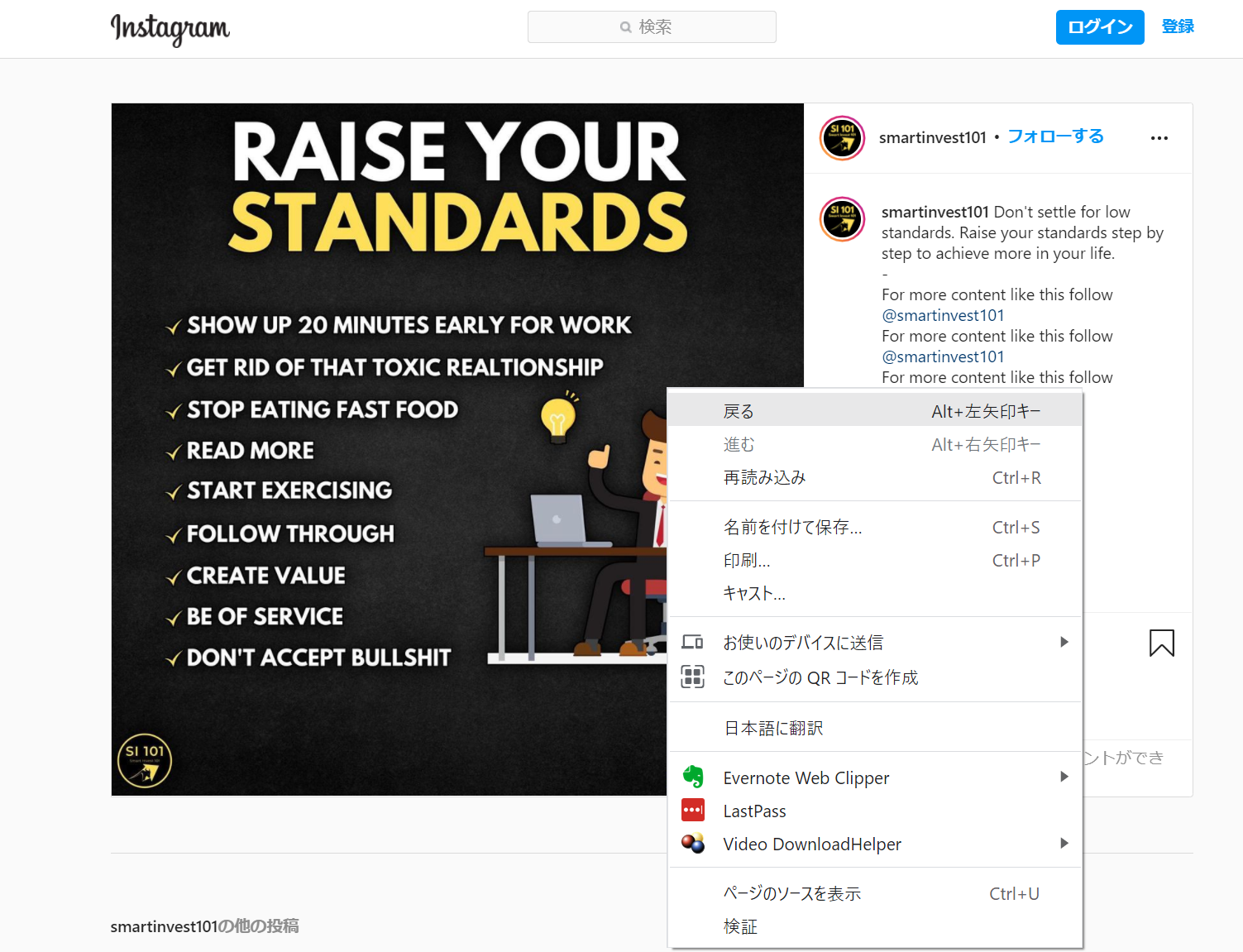
画面をスクリーンショットするなどで画像を保存することもできますが、Instagramの画像をダウンロードするPythonスクリプトを作成してみたので紹介したいと思います。
準備
今回のスクリプトではWebスクレイピングに欠かせないBeautifulSoup、Selenium、webdriverを使用するので、インストールしていない場合は以下のコマンドでインストールしておいてください。
|
1 2 3 |
python -m pip install bs4 python -m pip install selenium python -m pip install webdriver-manager |
プログラム
スクリプトの全体はこちらになります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
import shutil from selenium import webdriver from selenium.webdriver.chrome.options import Options from webdriver_manager.chrome import ChromeDriverManager from bs4 import BeautifulSoup import requests import time class InstagramImgDownloader: def __init__(self): options = Options() options.add_argument("--headless") # ブラウザを起動したくない場合 self.driver = webdriver.Chrome(ChromeDriverManager().install(), options=options) # ChromeDriverの起動 self.img_cnt = 1 def get_image(self, URL): self.driver.get(URL) time.sleep(2) soup = BeautifulSoup(self.driver.page_source, "html.parser") try: for image in soup.find_all('img', class_='FFVAD'): # class名を指定して、画像タグを取得する filename = "img_" + str(self.img_cnt) + ".jpg" # 保存するファイル名 image_link = image['src'] # 画像のURL response = requests.get(image_link, stream=True) # 画像を取得する with open(filename, "wb") as file: # 画像を保存する shutil.copyfileobj(response.raw, file) self.img_cnt += 1 break # 最初の画像だけをダウンロードする except Exception as e: print(e) print(str(self.img_cnt)+"番目の画像のダウンロードができませんでした。") print("画像のリンク:" + image_link) if __name__ == '__main__': URLs = ["https://www.instagram.com/p/CSzqOguCWzS/", "https://www.instagram.com/p/CSwI5Smixfi/", "https://www.instagram.com/p/CSbhHv6CU1J/", "https://www.instagram.com/p/CSgw2oAiZQb/", "https://www.instagram.com/p/CSaE7LAiDsy/", "https://www.instagram.com/p/CSP1uy4iMiD/", "https://www.instagram.com/p/CSSfTMhiXcQ/", "https://www.instagram.com/p/CRvvLfnqtTg/", "https://www.instagram.com/p/CQ_HiZpqaLj/", "https://www.instagram.com/p/CPZBuI2HPWr/"] insta = InstagramImgDownloader() for URL in URLs: insta.get_image(URL) |
スクリプトのダウンロードはこちらからどうぞ。
このスクリプトを実行すると、スクリプトと同じフォルダに10個の画像がダウンロードされます。

プログラムの説明
簡単にプログラムの内容を説明していきます。
まずは必要なライブラリモジュールをインポートします。
|
1 2 3 4 5 6 7 |
import shutil from selenium import webdriver from selenium.webdriver.chrome.options import Options from webdriver_manager.chrome import ChromeDriverManager from bs4 import BeautifulSoup import requests import time |
次にメインの処理をするクラスInstagramImgDownloaderを定義しています。まずコンストラクタでseleniumのwebdriverを起動しています。ここではブラウザは非表示(headless)で起動させています。img_cntという変数は画像を保存するときに名前に連番をつけるためのものです。
|
10 11 12 13 14 15 16 |
class InstagramImgDownloader: def __init__(self): options = Options() options.add_argument("--headless") # ブラウザを起動したくない場合 self.driver = webdriver.Chrome(ChromeDriverManager().install(), options=options) # ChromeDriverの起動 self.img_cnt = 1 |
InstagramImgDownloaderクラスのget_image関数は、InstagramのURLを渡すことでメインの画像をダウンロードし、ファイルに保存します。
|
18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
def get_image(self, URL): self.driver.get(URL) time.sleep(2) soup = BeautifulSoup(self.driver.page_source, "html.parser") try: for image in soup.find_all('img', class_='FFVAD'): # class名を指定して、画像タグを取得する filename = "img_" + str(self.img_cnt) + ".jpg" # 保存するファイル名 image_link = image['src'] # 画像のURL response = requests.get(image_link, stream=True) # 画像を取得する with open(filename, "wb") as file: # 画像を保存する shutil.copyfileobj(response.raw, file) self.img_cnt += 1 break # 最初の画像だけをダウンロードする except Exception as e: print(e) print(str(self.img_cnt)+"番目の画像のダウンロードができませんでした。") print("画像のリンク:" + image_link) |
Instagramのページに表示されるメインの画像ですが、ページのHTMLを表示してみると、画像の<img>タグには<class=”FFVAD”>が指定されているのが分かります。これを利用してBeautifulSoupで画像の部分を取り出しています。
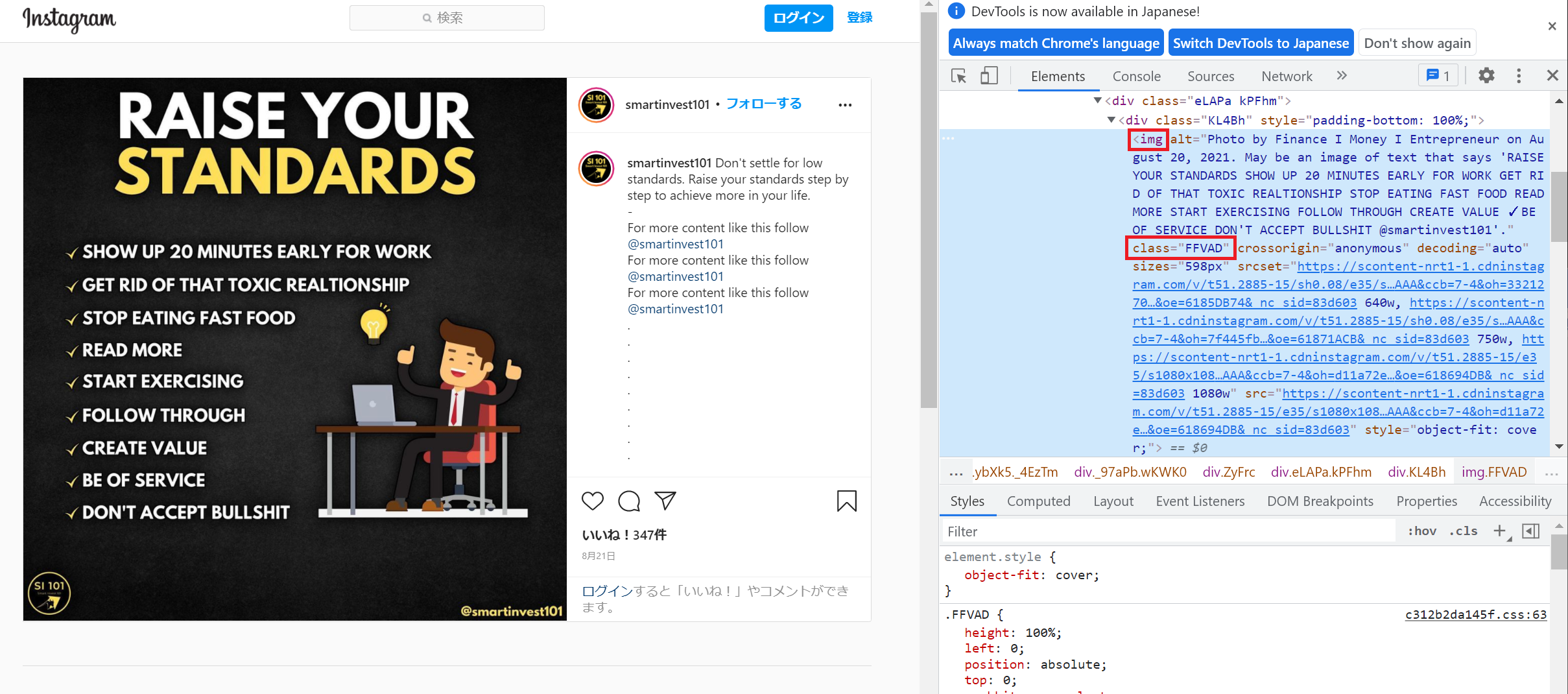
そしてダウンロードした画像データを、shutilモジュールのcopyfileobj関数を使ってファイルに保存しています(28、29行名)。
そのあとbreakしてforループを抜けている(31行目)のは、ここでストップしないとサムネイル画像までダウンロードしてしまうためです。
スクリプトが実行されたときの処理ですが、まず画像を保存したいインスタグラムのURLをリスト変数「URLs」に代入しています(41~50行目)。
その後、InstagramImgDownloaderクラスのインスタンスを作成し、forループでURLのリストから1つ1つURLを渡しています(51~53行目)。
|
40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
if __name__ == '__main__': URLs = ["https://www.instagram.com/p/CSzqOguCWzS/", "https://www.instagram.com/p/CSwI5Smixfi/", "https://www.instagram.com/p/CSbhHv6CU1J/", "https://www.instagram.com/p/CSgw2oAiZQb/", "https://www.instagram.com/p/CSaE7LAiDsy/", "https://www.instagram.com/p/CSP1uy4iMiD/", "https://www.instagram.com/p/CSSfTMhiXcQ/", "https://www.instagram.com/p/CRvvLfnqtTg/", "https://www.instagram.com/p/CQ_HiZpqaLj/", "https://www.instagram.com/p/CPZBuI2HPWr/"] insta = InstagramImgDownloader() for URL in URLs: insta.get_image(URL) |
さいごに
今回はPythonでWebスクレイピングをすることで、Webから直接画像をダウンロードしてみました。今回のプログラムを改変することで、ブラウザの操作では直接ダウンロードできない画像もダウンロードできるようになるかもしれません。誰かの参考になれば幸いです。
※注意1
画像には著作権があります。使用にはご注意ください。
※注意2
今回紹介したプログラムは2021年11月1日現在において動作することを確認していますが、今後InstagramページのHTML構造変化などによって動作しなくなる可能性もあります。その点はご了承ください。
- 投稿タグ
- プログラミング
