説明書や仕様書などページ数が多いPDFファイルは、よく参照する章だけを別ファイルとして抽出しておくと、ページ移動の手間が減って便利です。有料のAdobe Acrobatを使えばPDFファイルから特定のページを抽出することは簡単にできますが、無料のAcrobat Readerを使っている人も多いと思います。今回は勉強も兼ねて、PythonでPDFから特定のページを抽出するプログラムを作ってみたので紹介します。
動作
下記に示したプログラムを起動すると、以下のようなGUI画面が立ち上がります。
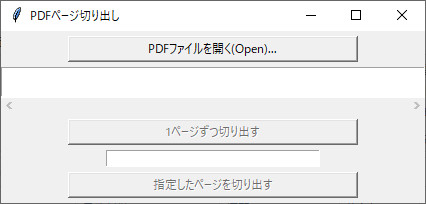
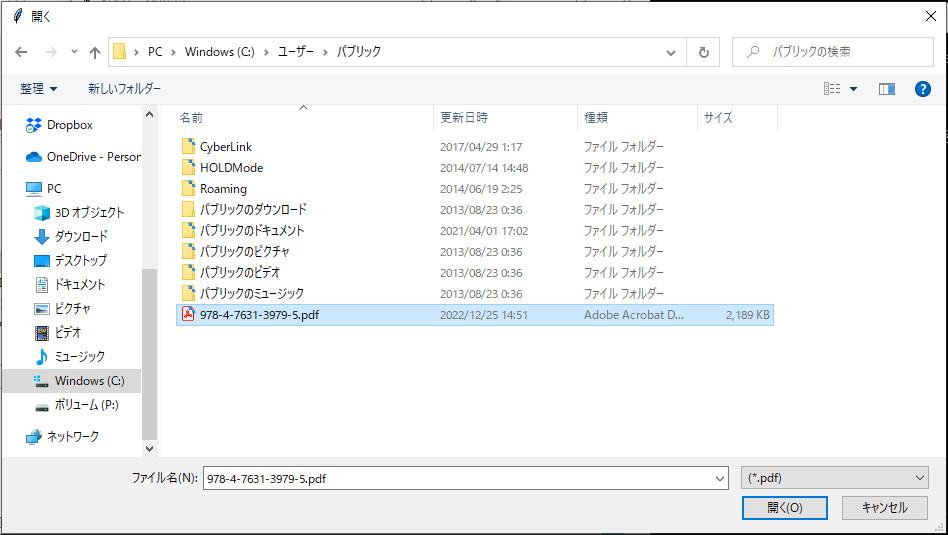
まず「PDFファイルを開く(Open)…」ボタンを押します。ファイルを選択するダイアログが表示されるので、PDFファイルを選択して読み込みます。
するとボタン下のテキストエリアに選択したファイルのパスとページ数が表示されます。
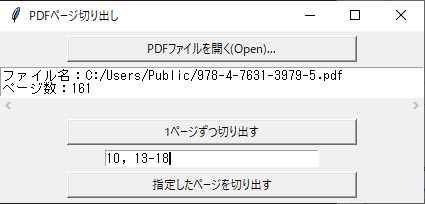
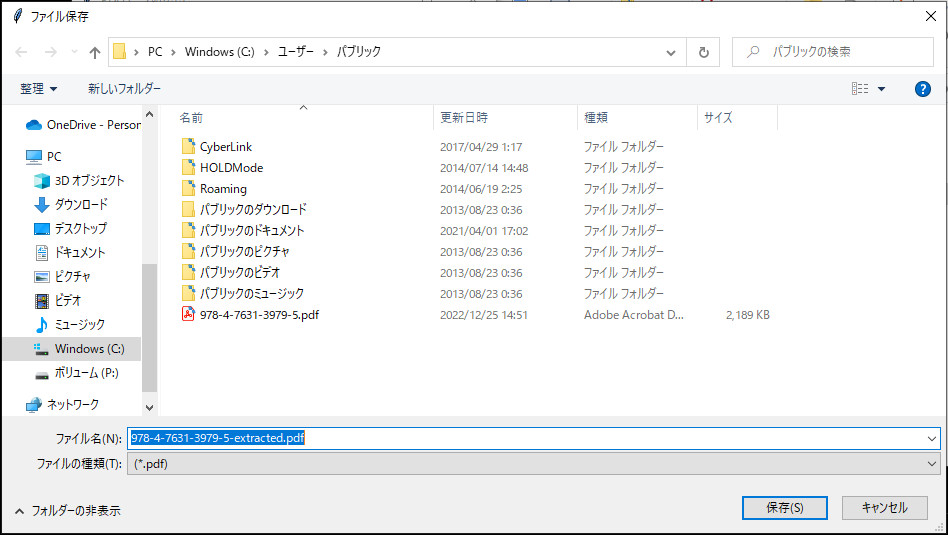
PDFファイルが開いたら任意のページを抽出することができます。たとえば10ページ目と13~18ページ目を抽出する場合は、下のほうにあるテキストボックスに半角で「10, 13-18」と入力して、「指定したページを切り出す」ボタンを押します。
するとファイル保存ダイアログが開くので場所を指定して保存してみてください。少し処理に時間がかかりますが、処理が終わるとそれを知らせるダイアログが出ます。出力されたファイルを確認して、指定したページが抽出されていることを確認してください。
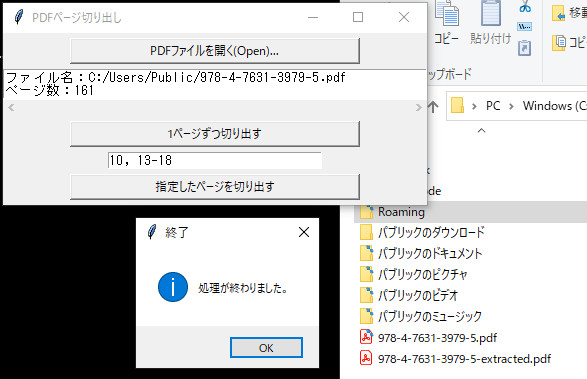
また「1ページずつ切り出す」ボタンを押すと、元のファイルと同じディレクトリに「元のファイル名_ページ数.pdf」という名前で全てのページを1枚ごとに個別のPDFファイルとして出力します。
なおページの指定を「15-1」のようにすれば15ページ目から1ページ目までページを逆順に入れ替えることもできます。こういったことは有料のAdobe Acrobatでもできないのではないでしょうか?
それでは以下にプログラムの内容を簡単に紹介しておきます。
準備
PyPDF2というモジュールを使用するので、以下のコマンドでインストールしてください。
|
1 |
pip install PyPDF2 |
プログラムのソースコード
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 |
from PyPDF2 import PdfWriter, PdfReader from io import StringIO import os import re import tkinter as tk import tkinter.filedialog as fd from tkinter import messagebox ############################################################################### # # メインのGUIクラス # ############################################################################### class PDF_page_splitter(): #-------------------------------------------------------------------------# # メインループ #-------------------------------------------------------------------------# def run(self): self.root.mainloop() #-------------------------------------------------------------------------# # 初期化 #-------------------------------------------------------------------------# def __init__(self): self.pdf_file_reader = None self.filename = "" self.dirpath = "" self.root = tk.Tk() self.root.title(u"PDFページ切り出し") self.frame1 = tk.Frame() self.frame1.pack() self.button_grep = tk.Button(self.frame1, text="PDFファイルを開く(Open)...", width=40, command=self.open_file) self.button_grep.pack(pady=5) self.frame2 = tk.Frame() self.frame2.pack() self.text = tk.Text(self.frame2, width=60, height=2, wrap=tk.NONE) self.xscroll = tk.Scrollbar(self.frame2, orient=tk.HORIZONTAL, command=self.text.xview) self.xscroll.pack(side=tk.BOTTOM, fill="x") self.text["xscrollcommand"] = self.xscroll.set self.text.pack(side='top') self.frame3 = tk.Frame() self.frame3.pack() self.button_split_each = tk.Button(self.frame3, text="1ページずつ切り出す", width=40, command=self.split_each_page) self.button_split_each.pack(pady=5) self.button_split_each['state'] = tk.DISABLED self.frame4 = tk.Frame() self.frame4.pack() self.specified_pages = tk.Text(self.frame4, width=30, height=1, wrap=tk.NONE) self.specified_pages.pack(side='top') self.frame5 = tk.Frame() self.frame5.pack() self.button_split_spec = tk.Button(self.frame5, text="指定したページを切り出す", width=40, command=self.split_specific_pages) self.button_split_spec.pack(pady=5) self.button_split_spec['state'] = tk.DISABLED #-------------------------------------------------------------------------# # プログラムの終了処理 #-------------------------------------------------------------------------# def exit_program(self): self.root.quit() exit() #-------------------------------------------------------------------------# # ファイル選択ダイアログ #-------------------------------------------------------------------------# def ask_input_filename(self, msg = None, types = [('', '*.pdf')]): rt = tk.Tk() rt.withdraw() filename = fd.askopenfilename(title = msg, filetypes = types) rt.destroy() return filename #-------------------------------------------------------------------------# # ファイル保存ダイアログ #-------------------------------------------------------------------------# def ask_output_filename(self, dir, filename, types = [('', '*.pdf')]): rt = tk.Tk() rt.withdraw() filename = fd.asksaveasfilename(title = 'ファイル保存', initialdir = dir, initialfile = filename, filetypes = types) rt.destroy() return filename #-------------------------------------------------------------------------# # PDFファイルを開く #-------------------------------------------------------------------------# def open_file(self): # テキストエリアをクリアする self.text.delete("1.0", "end") self.filename = self.ask_input_filename() if self.filename == "": return try: self.pdf_file_reader = PdfReader(self.filename) self.page_nums = len(self.pdf_file_reader.pages) info = f"ファイル名:{self.filename}\nページ数:{self.page_nums}" self.text.insert(tk.END, info) self.button_split_each['state'] = tk.NORMAL self.button_split_spec['state'] = tk.NORMAL except Exception as e: print(e) #-------------------------------------------------------------------------# # PDFファイルをページごとに切り出す #-------------------------------------------------------------------------# def split_each_page(self): if self.pdf_file_reader == None: return (name, extention) = os.path.splitext(self.filename) for num in range(self.page_nums): file_object = self.pdf_file_reader.pages[num] pdf_file_name = name + '-' + str(num+1) + '.pdf' pdf_file_writer = PdfWriter() with open(pdf_file_name, 'wb') as f: pdf_file_writer.add_page(file_object) pdf_file_writer.write(f) messagebox.showinfo("終了", "処理が終わりました。") #-------------------------------------------------------------------------# # PDFファイルを指定されたページに切り出す #-------------------------------------------------------------------------# def split_specific_pages(self): if self.pdf_file_reader == None: return # 保存するファイル (name, extention) = os.path.splitext(self.filename) pdf_file_name = name + '-extracted.pdf' filename = os.path.basename(pdf_file_name) dir_name = os.path.dirname(pdf_file_name) pdf_file_name = self.ask_output_filename(dir=dir_name, filename=filename) # キャンセルされた場合 if pdf_file_name == "": return # 指定されたページを取り出し、形式をチェックする str = self.specified_pages.get("1.0", "end") str = re.sub("\s", "", str) # スペース削除 pattern = "^(?!^[^\d])(?!.*[^\d]$)(?!.*\,-)(?!.*-\,)(?!.*--)[-\,\d]*$" result = re.match(pattern, str) spec_pages = [] if result: result_txt = result.group() result_lst = result_txt.split(',') for res in result_lst: res2 = res.split('-') if len(res2) > 1: p1 = int(res2[0]) p2 = int(res2[1]) if p1 < p2: for i in range(p1, p2+1): spec_pages.append(i-1) else: for i in range(p2, p1+1)[::-1]: spec_pages.append(i-1) else: spec_pages.append(int(res)-1) if len(spec_pages) == 0: return with open(pdf_file_name, 'wb') as f: pdf_file_writer = PdfWriter() for num in spec_pages: try: if 0 <= num and num < self.page_nums: file_object = self.pdf_file_reader.pages[num] pdf_file_writer.add_page(file_object) except Exception as e: print(e) pdf_file_writer.write(f) messagebox.showinfo("終了", "処理が終わりました。") ############################################################################### # # 以下、メイン処理 # ############################################################################### if __name__ == "__main__": app = PDF_page_splitter() app.run() |
プログラムの解説
PDFファイルの読み込み
|
102 103 104 105 106 |
try: self.pdf_file_reader = PdfReader(self.filename) self.page_nums = len(self.pdf_file_reader.pages) info = f"ファイル名:{self.filename}\nページ数:{self.page_nums}" self.text.insert(tk.END, info) |
103行目でPdfReaderによってPDFファイルを読み込んでいます。
104行目でPDFのページ数を調べています。
105~106行目でファイル名とページ数をテキストエリアに表示しています。
個別ページの抽出処理
|
116 117 118 119 120 121 122 123 124 125 126 127 128 129 |
def split_each_page(self): if self.pdf_file_reader == None: return (name, extention) = os.path.splitext(self.filename) for num in range(self.page_nums): file_object = self.pdf_file_reader.pages[num] pdf_file_name = name + '-' + str(num+1) + '.pdf' pdf_file_writer = PdfWriter() with open(pdf_file_name, 'wb') as f: pdf_file_writer.add_page(file_object) pdf_file_writer.write(f) messagebox.showinfo("終了", "処理が終わりました。") |
116~129行目:「1ページずつ切り出す」ボタンを押したときに呼び出されるのがsplit_each_pageというメソッドです。pdf_file_reader.pages[num]で特定のページ情報を取り出せます。取り出した情報をPdfWriterオブジェクトにadd_pageメソッドで追加し、writeメソッドで書き出しています。
指定したページの抽出処理
|
134 135 136 137 138 139 140 141 142 143 144 145 146 |
def split_specific_pages(self): if self.pdf_file_reader == None: return # 保存するファイル (name, extention) = os.path.splitext(self.filename) pdf_file_name = name + '-extracted.pdf' filename = os.path.basename(pdf_file_name) dir_name = os.path.dirname(pdf_file_name) pdf_file_name = self.ask_output_filename(dir=dir_name, filename=filename) # キャンセルされた場合 if pdf_file_name == "": return |
「指定したページを切り出す」ボタンを押したときに呼び出されるのがsplit_specific_pagesというメソッドです。
139~146行目で元のファイル名の末尾に「-extracted」と付けたファイル名を作成し、保存ダイアログを表示します。
|
148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 |
# 指定されたページを取り出し、形式をチェックする str = self.specified_pages.get("1.0", "end") str = re.sub("\s", "", str) # スペース削除 pattern = "^(?!^[^\d])(?!.*[^\d]$)(?!.*\,-)(?!.*-\,)(?!.*--)[-\,\d]*$" result = re.match(pattern, str) spec_pages = [] if result: result_txt = result.group() result_lst = result_txt.split(',') for res in result_lst: res2 = res.split('-') if len(res2) > 1: p1 = int(res2[0]) p2 = int(res2[1]) if p1 < p2: for i in range(p1, p2+1): spec_pages.append(i-1) else: for i in range(p2, p1+1)[::-1]: spec_pages.append(i-1) else: spec_pages.append(int(res)-1) |
その後、テキストエリアに入力されたページ数を取り出すための処理が149~169行目です。正規表現を使って、コンマおよびハイフンで区切られた数字を取り出しています。ハイフンで区切られた場合はその間の数字も展開してページに指定します。たとえば「10-15」とあれば、それを「10, 11, 12, 13, 14, 15」に展開して、変数spec_pagesに格納します。
コンマやハイフンで区切られた数値の文字列を取り出す正規表現は以下になります。
|
1 |
^(?!^[^\d])(?!.*[^\d]$)(?!.*\,-)(?!.*-\,)(?!.*--)[-\,\d]*$ |
それぞれの意味は以下になります。
- (?!^[^\d]) → 文字列の先頭は数字以外認めない
- (?!.*[^\d]$) → 文字列の末尾は数字以外認めない
- (?!.*\,-) → 文中で「,-」と続くのは禁止
- (?!.*-\,) → 文中で「-,」と続くのは禁止
- (?!.*–) → 文中で「–」と続くのは禁止
- [-\,\d]* → 以上の条件を踏まえた上で、文字列は「-」「,」「数字」だけで構成される
このあたりの処理は、以下のサイトを参考にさせていただきました。
|
174 175 176 177 178 179 180 181 182 183 |
with open(pdf_file_name, 'wb') as f: pdf_file_writer = PdfWriter() for num in spec_pages: try: if 0 <= num and num < self.page_nums: file_object = self.pdf_file_reader.pages[num] pdf_file_writer.add_page(file_object) except Exception as e: print(e) pdf_file_writer.write(f) |
ファイルの出力についてはsplit_each_pageメソッドの処理を少し改変して実現しています。
- 投稿タグ
- プログラミング
