最近は電子書籍が普及して、スマホやKindleなど画面上で本を読むことが多くなりました。私のお気に入りの雑誌「週刊アスキー」のなかに「JavaScriptの部屋」という記事があり、毎回、「JavaScriptでこんなこともできるのか」と驚かされるような興味深い内容が掲載されています。ただ、ダウンロードできるファイルとしてソースコードが提供されていないので、雑誌を見ながら手打ちでソースコードを打ち込む必要があります。これが結構大変なのですが、ふと「これ、OCR※で自動的に文字を認識できたら楽なんじゃない?」と思い、画像から文字を抜き出すプログラムをPythonで作ってみたので、今回紹介したいと思います。
※ OCR(Optical Character Recognition/Reader、オーシーアール、光学的文字認識)とは、手書きや印刷された文字を、コンピュータが利用できるデジタルの文字コードに変換する技術。
準備
今回はオープンソースのOCRエンジンであるTesseract(テッセラクト)を使用します。準備の手順は以下の通りです。
- Tesseractをダウンロードする
Tesseract: https://tesseract-ocr.github.io/tessdoc/Home.html
Windowsのインストーラーは以下のURLからダウンロードできます。
https://github.com/UB-Mannheim/tesseract/wiki - ダウンロードしたファイルを実行して、インストールする。
- 日本語の訓練データを以下のURLからダウンロードする
https://github.com/tesseract-ocr/tessdata_best/blob/main/jpn.traineddata - インストールされたフォルダ(デフォルトでは「C:\Program Files\Tesseract-OCR」)内にある「tessdata」フォルダに「jpn.traineddata」を配置する。
またPythonモジュールとして「pyocr」を使うので、以下のコマンドでインストールします。
|
1 |
pip install pyocr |
使い方
実行すると以下のようなGUIが立ち上がります。
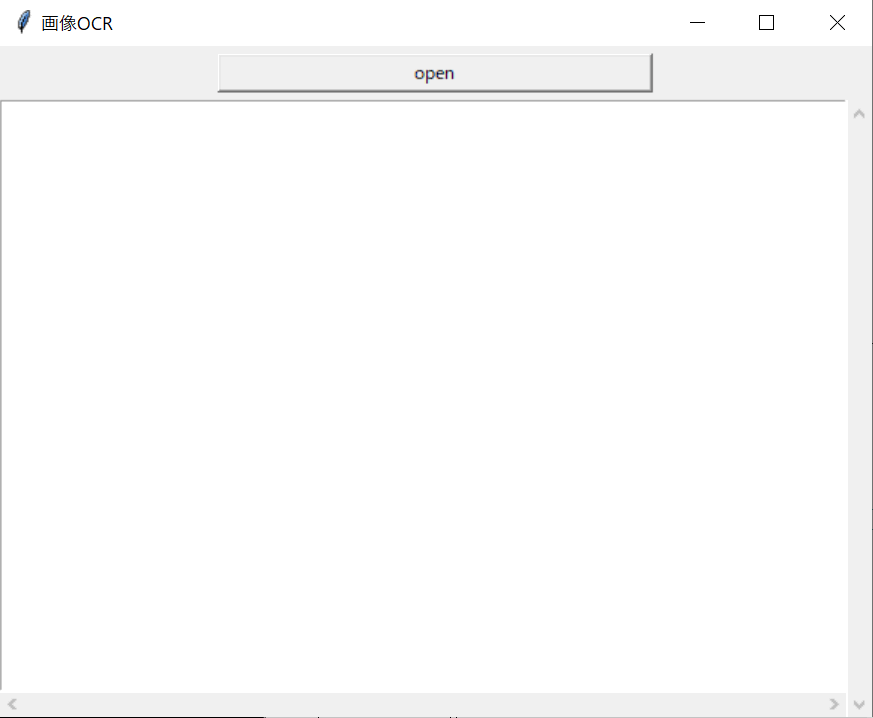
ボタンを押すと画像ファイルを選択するダイアログが開くので、文字が含まれる画像を選んでください。複数のファイルにも対応しています。複数のファイルを選択するときは、コントロールボタンを押したまま、逆順(最後のファイルから)にファイルを選択していってください。選択後、ファイルを選んで「開く」ボタンを押すとOCR処理が始まります。
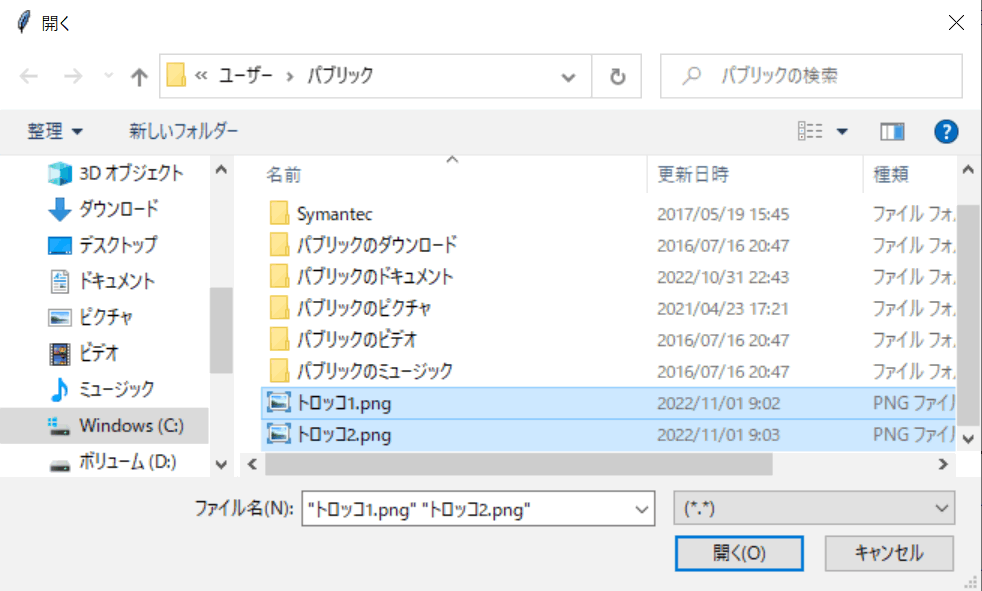
ここでは以下の2つの画像ファイルを読み込んでみました。


しばらく時間が経つと、テキストエリアに結果が表示されます。
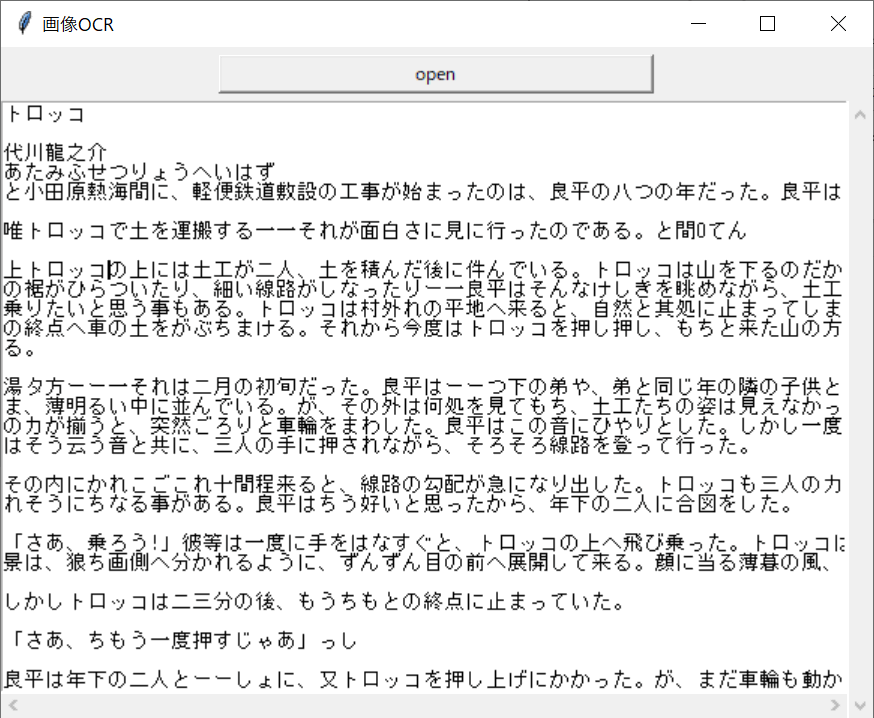
結果を見ると、ところどころ間違った文字に認識されているところもありますが、概ねきちんと認識されているようです。
ソースコード
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 |
#ライブラリインポート import pyocr from PIL import Image, ImageEnhance import os import tkinter as tk import tkinter.filedialog as fd from tkinter import messagebox import subprocess #Pah設定 TESSERACT_PATH = r'C:\Program Files\Tesseract-OCR' #インストールしたTesseract-OCRのpath TESSDATA_PATH = r'C:\Program Files\Tesseract-OCR\tessdata' #tessdataのpath os.environ["PATH"] += os.pathsep + TESSERACT_PATH os.environ["TESSDATA_PREFIX"] = TESSDATA_PATH ############################################################################### # # メインのGUIクラス # ############################################################################### class GUI_grep(): def get_string_ocr(self, filename): img = Image.open(filename) img_g = img.convert('L') #Gray変換 enhancer= ImageEnhance.Contrast(img_g) #コントラストを上げる img_con = enhancer.enhance(2.0) #コントラストを上げる #画像からOCRで日本語を読んで、文字列として取り出す txt_pyocr = self.tool.image_to_string(img_con , lang='jpn', builder=self.builder) #半角スペースを消す txt_pyocr = txt_pyocr.replace(' ', '') print(txt_pyocr) return txt_pyocr #-------------------------------------------------------------------------# # メインループ #-------------------------------------------------------------------------# def run(self): self.root.mainloop() #-------------------------------------------------------------------------# # 初期化 #-------------------------------------------------------------------------# def __init__(self): #OCRエンジン取得 self.tools = pyocr.get_available_tools() self.tool = self.tools[0] #OCRの設定 ※tesseract_layout=6が精度には重要。デフォルトは3 self.builder = pyocr.builders.TextBuilder(tesseract_layout=6) self.root = tk.Tk() self.root.title(u"画像OCR") self.frame1 = tk.Frame() self.frame1.pack() self.button_grep = tk.Button(self.frame1, text="open", width=40, command=self.process_files) self.button_grep.pack(pady=5) self.frame2 = tk.Frame() self.frame2.pack() self.text = tk.Text(self.frame2, width=80, height=30, wrap=tk.NONE) self.yscroll = tk.Scrollbar(self.frame2, orient=tk.VERTICAL, command=self.text.yview) self.yscroll.pack(side=tk.RIGHT, fill="y") self.xscroll = tk.Scrollbar(self.frame2, orient=tk.HORIZONTAL, command=self.text.xview) self.xscroll.pack(side=tk.BOTTOM, fill="x") self.text["yscrollcommand"] = self.yscroll.set self.text["xscrollcommand"] = self.xscroll.set self.text.pack(side='top') #-------------------------------------------------------------------------# # プログラムの終了処理 #-------------------------------------------------------------------------# def exit_program(self): self.root.quit() exit() #-------------------------------------------------------------------------# # ファイル選択ダイアログ #-------------------------------------------------------------------------# def ask_input_filenames(self, msg = None, types = [('', '*.*')]): rt = tk.Tk() rt.withdraw() filenames = fd.askopenfilenames(title = msg, filetypes = types) rt.destroy() return filenames #-------------------------------------------------------------------------# # Grep検索する #-------------------------------------------------------------------------# def process_files(self): # テキストエリアをクリアする self.text.delete("1.0", "end") filenames = self.ask_input_filenames() if len(filenames) == 0: return for file in filenames: try: text = self.get_string_ocr(file) self.text.insert(tk.END, text) except: pass messagebox.showinfo("終了", "処理が終わりました。") ############################################################################### # # 以下、メイン処理 # ############################################################################### if __name__ == "__main__": app = GUI_grep() app.run() |
ソースコードの説明
12,13行目でインストールしたTesseractの実行ファイルがあるフォルダのパスと機械学習の学習済みデータが入っているパスを指定します。デフォルトでは以下の通りですが、違う場所にインストールした場合はそのパスを指定してください。
|
11 12 13 14 15 16 |
#Pah設定 TESSERACT_PATH = r'C:\Program Files\Tesseract-OCR' #インストールしたTesseract-OCRのpath TESSDATA_PATH = r'C:\Program Files\Tesseract-OCR\tessdata' #tessdataのpath os.environ["PATH"] += os.pathsep + TESSERACT_PATH os.environ["TESSDATA_PREFIX"] = TESSDATA_PATH |
26~39行目にあるget_string_ocrメソッドがOCR処理をする関数です。
|
26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
def get_string_ocr(self, filename): img = Image.open(filename) img_g = img.convert('L') #Gray変換 enhancer= ImageEnhance.Contrast(img_g) #コントラストを上げる img_con = enhancer.enhance(2.0) #コントラストを上げる #画像からOCRで日本語を読んで、文字列として取り出す txt_pyocr = self.tool.image_to_string(img_con , lang='jpn', builder=self.builder) #半角スペースを消す txt_pyocr = txt_pyocr.replace(' ', '') print(txt_pyocr) return txt_pyocr |
まずPIL(Python Image Library)ライブラリで画像を開いた後、グレースケールに変換し、さらにコントラストを上げる処理をしています。その後、OCRエンジンのimage_to_string関数で画像から文字を抜き出しています。第2引数に「lang=’jpn’」を指定することで、【準備】でインストールした学習データ「jpn.traineddata」を使用するようになるので、日本語を認識してくれます。
またimage_to_string関数で抜き出された文字列は文字と文字のあいだにスペースが入っているので、replaceメソッドでそれを取り除く処理をしています。
さいごに
このプログラムを使って「週刊アスキー」の「JavaScriptの部屋」に掲載されているソースコードをOCR処理してみました。「,(コンマ)」を「.(ピリオド)」と認識したり、「ID(アイ・ディー)」を「lD(小文字のエル・ディー)」と認識したり、「i(小文字のアイ)」を「;(セミコロン)」と認識したり、うまくいかないところもありますが、全て手打ちするよりは遥かに効率的にソースコードを書き写すことができるようになり、とても満足です。
- 投稿タグ
- プログラミング
