GoogleやBingなどの検索エンジンで画像を検索する人も多いと思います。好きな動物やアイドルの写真を集めている人もいるのではないでしょうか。中にはお気に入りの写真を何枚もダウンロードする人もいるかもしれませんね。でも1つ1つ画像をダウンロードするのは結構めんどうな作業ですよね。
そこで今回は、特定のキーワードに引っかかった画像をインターネットから大量に取ってくるPythonプログラムを作ってみました。
準備
今回のプログラムでは icrawler というモジュールを使います。
https://icrawler.readthedocs.io/en/latest/builtin.html#search-engine-crawlers
以下のコマンドでインストールできます。
|
1 |
pip install icrawler |
プログラムの内容
今回のプログラムは10行程度と、とてもシンプルです。
|
1 2 3 4 5 6 7 8 9 |
from icrawler.builtin import BingImageCrawler dirname = 'images' # 画像を保存するディレクトリ bing_crawler = BingImageCrawler(downloader_threads=4, storage={'root_dir': dirname}) keyword = 'Yosemite' # 検索キーワード bing_crawler.crawl(keyword=keyword, filters=None, offset=0, max_num=100, min_size=(1024, 768), max_size=None, file_idx_offset='auto') |
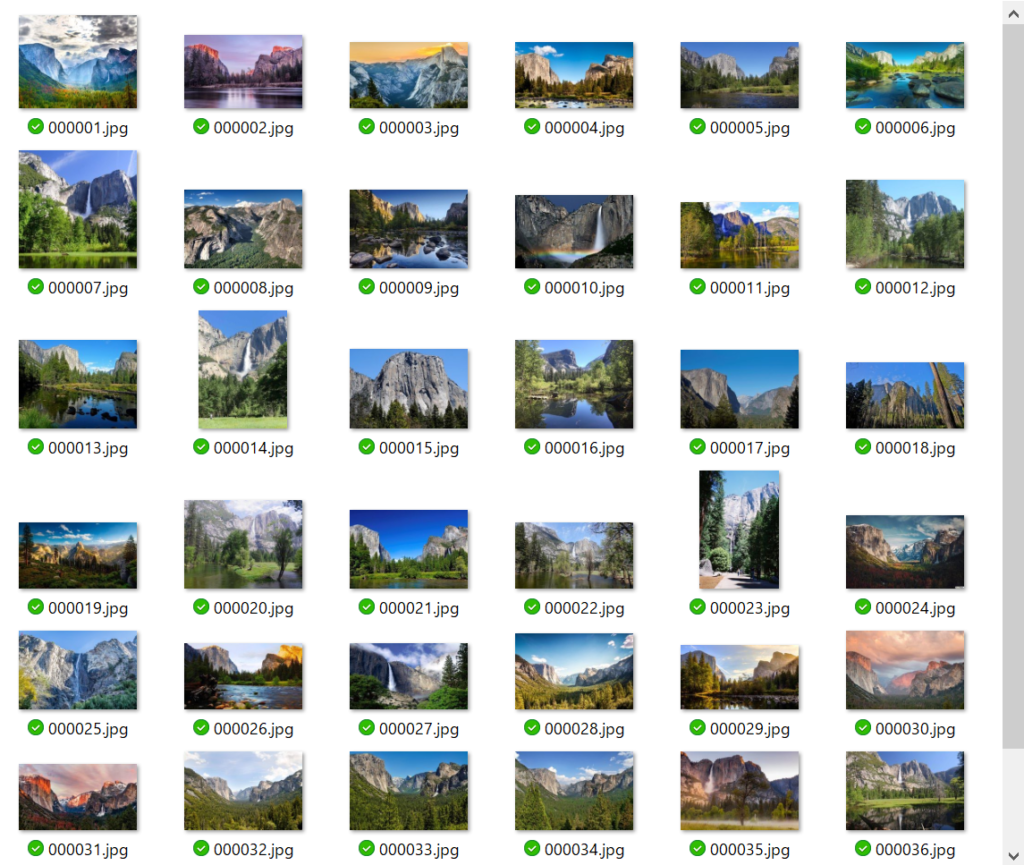
このプログラムを実行すると、数十秒で多くの画像がダウンロードされます。
プログラムの説明
それでは簡単に内容を説明していきます。
icrawlerではGoogle、Bing、Baiduという世界中で使われている検索エンジンで、画像検索ができます。今回はBingImageCrawlerを使いましたが、GoogleImageCrawlerとBaiduImageCrawlerもあります。使い方はほぼ同じようです。
|
3 4 |
dirname = 'images' # 画像を保存するディレクトリ bing_crawler = BingImageCrawler(downloader_threads=4, storage={'root_dir': dirname}) |
画像を保存するフォルダの名前(パス)を指定して、ImageCrawlerのオブジェクトを作成しています。ここではPythonスクリプトと同じディレクトリにある「images」というフォルダに画像をダウンロードするようにしています。
|
6 7 8 9 |
keyword = 'Yosemite' # 検索キーワード bing_crawler.crawl(keyword=keyword, filters=None, offset=0, max_num=100, min_size=(1024, 768), max_size=None, file_idx_offset='auto') |
検索キーワードを指定し、crawl関数を呼び出すと画像が指定したフォルダに保存されていきます。
crawl関数にはいくつものオプションがあります。
- max_num:取得する画像の最大数(上限は1000)
- min_size:取得する画像の最小サイズ
- max_size:取得する画像の最大サイズ
- file_idx_offset: ‘auto’を指定すると、繰り返しプログラムを実行しても続きの番号から画像を保存してくれます。0を指定すると、すでにフォルダに画像がある場合は新たに画像はダウンロードされないようです。
また、必ずしもmax_numで指定した数だけ画像がダウンロードできるわけではありません。上記のサンプルプログラムではmax_numを100にしていますが、実際にダウンロードされたのは38枚でした。

またfiltersには以下のようなオプションを設定できるようです。詳しくはこちらのページを参照してください。

さいごに
今回紹介したプログラムは、広末涼子の大ファンだった大学生のころの私が手にしたら泣いて喜ぶプログラムでしょう(GoogleもBingもまだ存在していなかった時代ですが・・・)。
今回の記事が誰かのお役に立てば幸いです。
※インターネット上の画像には著作権や肖像権がある場合があります。画像の使用にはご注意ください。
- 投稿タグ
- プログラミング
